Why Big O is important in software engineering
Big O notation often comes up in software engineering. Engineers, especially self taught engineers, may fail to see its importance. Some might even be tempted to think it’s an academic exercise, playing no role in day to day software engineering. And in some sense, they may be right. For a while, I left the topic since I had no strong interest in big tech (at that point in my career and since that is where the topic is most likely to come up). Creating algorithms from the ground up is something many engineers do not do in their day to day work. However, the moment you begin to create or edit algorithms and data structures, big O is a concept that should take the center stage in your mind. When I went deeper into backend engineering from a primarily frontend role, I was forced to start thinking about how efficient my programmes were running. How well they would suit our purposes, how fast they would run, how much space they consumed, etc.
Big O represents the space and time complexity of your application. It primarily cares about worst case scenario, so it ignores constants and focuses more on how the complexity grows as your input grows. This is why big O notation is not the only way to optimize an algorithm and even when you have the best possible notation, there could still be more you could do to improve the algorithm’s performance. Big O notation does not help you create efficient algorithms by itself. Instead, if you understand big O, you’re able to understand how your programme will run in its worst case scenario. You’re also able to decide what algorithm is most efficient for your particular purpose, since you know the context in which the programme will run. Without understanding big O, you will be unable to understand the performance implication of the programmes you write.
A constant algorithm is represented by O(1). This is because no matter how large the input passed becomes, the time it takes for the function to run will not change. An example of this is a push operation in JavaScript. JavaScript does not need to loop over an array to append a value to the end of the array. Because of this, no matter how large the array is, the time it takes will be pretty much constant. However, a shift operation is O(n), with n representing the number of values in the input. This is because the programme has to loop over each value and reassign new indexes to those values. Therefore, if there are 50 values, it would be O(50). If there are 1,000 values, it would be O(1000). This knowledge allows you make more efficient decisions when adding values to an array. Knowing this helps you understand that if the position is not particularly important, then it is better than add a value to the end of your array than to the beginning of your array.
If you have a loop within a loop, your big O notation becomes O(n^2) or O(a*b), depending on if it is the same input being looped over both times. This means the time complexity of your function will increase at an exponential value. In such a case, where it is possible to avoid a loop within a loop by having your two loops follow each other, you may realize that this is better with your knowledge of big O. Regardless of the number of loops within a function, the function will remain O(n) or O(a+b), as long as no loop is within another.
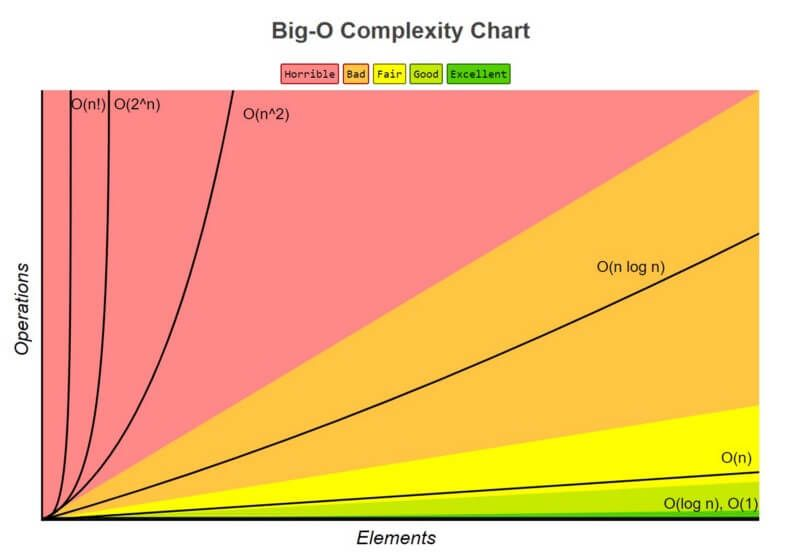
The big O complexity chart shows how functions grow as their inputs grow. The optimal functions are usually O(log n) and O(1). The efficiency reduces as you go higher on the chart, from green, to yellow, to amber, to red. Some algorithms cannot be constant time, and you will have to be satisfied with the most efficient notation you can take it to. An important point to consider is that in the chart, all notations begin at the same point and only diverge as they grow. This is because when the input is small, the O notation is irrelevant. As earlier stated, big O notation is only concerned about the worst case scenario as your function grows.
An unreliable way to determine how efficient a function is would be to check the speed of the different functions. Yet, this is the intuitive way. If a friend and I wanted to see whose function is more efficient, and we had no knowledge of big O notation, we would definitely compare our functions by speed to see whose function ran faster. I have done this. Big O lets us know that this way of measuring efficiency is unreliable, and why it is unreliable. Besides the different computers and resources the functions might be running on, which may be difficult to predict where the program will eventually run, big O shows us how our function will grow as it accepts more input. My friend’s function might be faster up to 10,000 input values, and then suddenly start declining rapidly as the input values grow beyond that, while my function could grow very steadily, eventually outperforming their function at 20,000 input values. If our function would ideally take about 50,000 inputs in production, my function would be better. But without big O, we wouldn’t know this, and I would cast aside my more efficient function for his.
Besides algorithms, knowledge of big O notation can also help you make the best decision when choosing the appropriate data structure for your data. Without O notations, people will often choose the data structure that is simplest to use. However, with big O notation, we know that tolerating the initial complexity of some data structures will mean better performance in some contexts. We can have all the information we need to make better tradeoffs. For example, most people without knowledge of big O notation will use an array in every situation they need an iterable data structure for loop actions. However, this will be akin to using a hammer to drive all nails, including screws, in, when you should consider a screw driver in some cases. Linked Lists have comparatively quicker insertions and deletes, with constant notations of O(1). However, any insert operation on an array that is not added to the very end will have a O(n) notation. Even some append operations on arrays may have a O(n) notation. On the other hand, arrays have fast lookups with O(1) notation (and comparatively faster loops despite being O(n)) while Linked Lists have slow lookups of O(n) with comparatively slower loops despite also being O(n). Array loops being faster than linked list loops is something I can only guarantee for JavaScript, because of how the language works under the hood. Values close to each other by index are stored close to each other in memory, in a JavaScript array, which makes them more quickly retrievable. Therefore, the right data structure for your situation would depend on the operations you would be performing most often. If you would be performing look up operations a majority of the time, then arrays could be better for you. However, if a majority of your operations are inserts and deletes, then a linked list could be better for your situation.
Big O notation is important for software engineers because it gives more knowledge to make decisions. It improves the mental model used to perceive algorithms, allowing engineers to choose the most efficient algorithms and data structures for programmes.